Machine learning model deployment isn’t just the last box to check; it’s how we get a theoretical model to actually do something in the real world. This critical stage often trips people up, turning promising models into duds. This is because deployment takes more than just tech skills; it also needs a solid grasp of where the model will live and what problems might crop up along the way. So, why do so many models fall flat after deployment?
Bridging the Gap Between Training and Production
One common trap is the difference between training environments and the reality of production. Models trained on pristine datasets often struggle with the wild west of real-world data. Think of it like this: a fraud detection model trained on old data might completely miss new scams. Plus, the computing power in production might be totally different from what you used for training, creating performance bottlenecks. This shows why it’s important to think about real-world limitations before you even start deploying.
Infrastructure and Cross-Functional Skills
Successful deployment depends on solid infrastructure and teamwork. A team with skills in areas like software engineering, DevOps, and data engineering is essential. They make sure the model works with the systems you already have. Spotting potential issues early on, like slow data or limited processing power, is also key to avoid expensive delays and having to redo things. This proactive approach helps teams smooth out the deployment process and minimize hiccups.
The importance of machine learning model deployment is clear from how fast the market is growing. The global machine learning market is expected to hit $113.10 billion in 2025 and a whopping $503.40 billion by 2030, with a CAGR of 34.80%. This growth shows the rising need for smart automation and data-driven choices across different industries, from banking and healthcare to retail and manufacturing. You can check out more detailed stats here: https://www.itransition.com/machine-learning/statistics This rapid expansion makes it even more important to understand the ins and outs of deployment to get the most out of your machine learning projects.
Ensuring Long-Term Model Success
Ultimately, successful deployment takes careful planning, precise execution, and constant monitoring. By tackling potential problems head-on and building a collaborative culture, companies can make sure their models don’t just survive in production – they thrive. This means doing more than just launching a model; it means actively managing and tweaking its performance over time.
Deployment Strategies That Actually Work
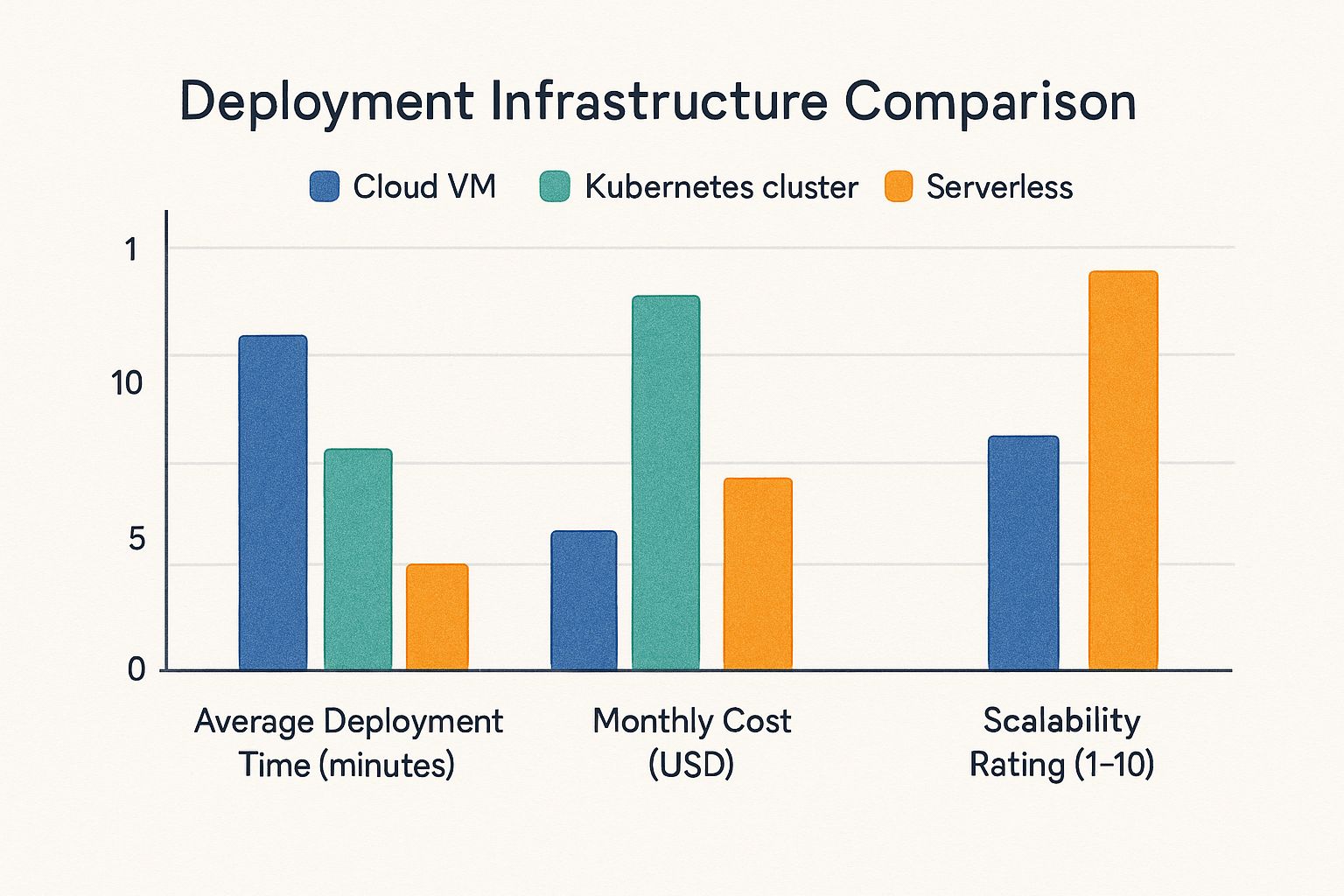
This infographic gives you a quick rundown of three popular ways to set up your machine learning model: Cloud VMs, Kubernetes clusters, and Serverless functions. It compares them based on how long they take to deploy, how much they cost, and how easily they scale. Serverless looks great for speed and scaling, but the costs can add up. Kubernetes finds a nice balance between scaling and cost, while Cloud VMs give you tons of control, but you’ll be doing more of the management yourself. The key takeaway here? Pick the infrastructure that best fits your project.
Choosing The Right Deployment Strategy
Picking the right way to deploy your model is a big deal if you want it to be successful. Think about things like how much you need it to scale, your budget, and what your application actually needs. For example, serverless deployment using platforms like AWS Lambda or Azure Functions is super scalable if your app has traffic that goes up and down a lot. Plus, you only pay for what you use, which is great if your traffic isn’t constant.
Leveraging Containerization For Consistent Environments
Sometimes you need more control over your environment. That’s where containerization with Docker and Kubernetes comes in. Docker packages your model and everything it needs into a neat little container, so it runs the same everywhere. Then, Kubernetes handles the deployment and scaling of those containers, making management simpler and keeping things running smoothly. This setup is perfect for complex apps or if you need to keep tight control over versions. On a related note, this article on explainable AI in healthcare might be interesting: How to master explainable AI in healthcare.
Versioning, Dependency Management, And Edge Deployment
Version control for your models is a must. It lets you track changes, go back to older versions if something goes wrong, and make sure everything is reproducible. Good dependency management, using tools like pip and conda, avoids those “works on my machine” headaches by clearly listing all the libraries you need. This makes deployment smoother and ensures your model behaves consistently across different environments. And if your application is sensitive to lag, consider edge deployment. This puts your model directly on the device collecting data, cutting down on lag and enabling real-time processing. This is super important for things like self-driving cars or factory automation.
The following table offers a more structured comparison of the various approaches:
Comparison of Model Deployment Strategies
A comprehensive comparison of different machine learning model deployment approaches based on key factors such as scalability, maintenance requirements, and cost implications
Deployment Strategy
Scalability
Maintenance Complexity
Cost Implications
Ideal Use Cases
Cloud VMs
Moderate
High
Moderate to High
Applications requiring high control and customization
Kubernetes Clusters
High
Moderate
Moderate
Complex applications, microservices architecture
Serverless Functions
High
Low
Pay-per-use (can be high with frequent invocation)
Event-driven applications, fluctuating workloads
This table highlights the trade-offs between different deployment options, emphasizing how scalability and maintenance needs influence cost and suitability for various use cases. Choosing the right strategy depends on your specific needs.
Did you know 92% of companies plan to invest more in AI in the next three years? That includes machine learning model deployment! Check out this McKinsey article for more. This increasing investment shows how important it is to have solid deployment strategies that can handle increasingly complex and large-scale machine learning applications. As AI keeps growing, deploying and managing models effectively will be a key factor for businesses that want to use the power of AI to their advantage.
MLOps: The Bridge Between Data Science and Production
Getting a machine learning model up and running is just the first step. What really matters is creating a sustainable connection between data science and production. This means getting your data scientists, IT operations, and everyone else involved to work together. Smart teams are ditching the old ways of working in silos for smoother workflows. This teamwork speeds up how fast you can deploy models while keeping things high-quality and reliable.
Streamlining the Path to Production With MLOps
A big part of this collaborative approach is MLOps (Machine Learning Operations). Think of it as bringing the best practices from DevOps into machine learning. This helps automate a lot of the model development and deployment steps, so you get quicker releases and a more solid system. For instance, using continuous integration pipelines built for ML can catch and fix problems early in development, before they become a headache in production.
Automating Testing and Monitoring for Enhanced Model Reliability
Automated testing frameworks are essential for MLOps. They don’t just check your code, but also how your model actually behaves. This is huge for making sure your model works as expected in real-world situations. On top of that, monitoring systems are key for spotting small dips in performance before they impact your users. This proactive monitoring lets you step in quickly and prevent potentially bigger problems later. When figuring out your deployment strategy, check out the advantages of things like Edge Computing.
MLOps Implementation: A Roadmap for Success
Different organizations are at different stages with MLOps, so they need different strategies. Some might just be starting to automate things, while others are looking to fully integrate MLOps into how they already work. There’s no one-size-fits-all approach, and how you successfully adopt MLOps will depend on your specific needs and what resources you have. But no matter how far along you are, a crucial part of adopting MLOps is a cultural shift toward working together and sharing responsibility.
The Growth and Importance of MLOps
MLOps is becoming super important, and it’s growing rapidly. The market for machine learning model operationalization management (MLOps) is projected to leap from $2.65 billion in 2024 to $3.83 billion in 2025, a CAGR of 44.8%. This huge growth is fueled by the increasing number and complexity of ML models, growing data volumes, and the bigger need for automation. Want more stats? Check this out: https://www.thebusinessresearchcompany.com/report/machine-learning-development-global-market-report. The MLOps market is expected to hit $16.74 billion by 2029. Key trends include better model explainability, integration with AI governance, and a growing emphasis on model versioning. These advancements make MLOps even more crucial for successfully deploying machine learning models. By adopting MLOps principles, organizations can effectively manage the entire life cycle of their ML models, ensuring they stay reliable, efficient, and deliver consistent value over time. This means automating model training and deployment, better integrating with DevOps practices, and focusing on model governance and compliance.
The Deployment Toolkit: Tools That Make the Difference
Picking the right tools for deploying your machine learning model can really make or break your project. This section dives into the must-have tools that smooth out the process, from getting your model up and running to packaging it up and managing the whole lifecycle. We’ll look at their pros, cons, and how they fit into a solid deployment pipeline.
Model Serving: The Foundation of Deployment
Model serving platforms are the bedrock of deployment. They let your models handle real-world requests. TensorFlow Serving and TorchServe, for example, are tuned for their respective deep learning frameworks, offering efficient handling of predictions and model management. But, they need specific setups and might not be the best fit for every situation.
Let’s say you’re using a different framework like scikit-learn. A more general tool like BentoML or MLeap might be a better choice. These offer more flexibility and can package models from different frameworks for deployment. Finding the right tool depends on your project’s needs and how complex your models are.
Containerization: Ensuring Consistency and Portability
Containerization tools like Docker and Kubernetes are essential for making sure your model behaves the same way across different environments. Docker bundles your model and its dependencies into a container, making it easy to deploy on any system that has Docker. This gets rid of the “it works on my machine” headache and simplifies handing things off between development and production.
A key part of your deployment pipeline is a solid CI Server. Kubernetes manages the deployment, scaling, and overall management of these containers, making it a must-have for complex deployments. This is especially helpful with multiple models, microservices, or apps that need to scale big. However, Kubernetes adds another layer of complexity, needing dedicated resources and know-how.
End-to-End MLOps Platforms: Streamlining the Entire Process
Platforms like MLflow and Kubeflow aim to provide a complete solution for the machine learning lifecycle, including deployment. These tools offer features for tracking models, managing experiments, and automating pipelines. Check this out: How to master AI product development. They can simplify tricky deployments, particularly in larger companies with many teams and projects. But, these platforms can be resource-heavy and need a fair bit of initial setup to work with your existing systems.
Choosing the Right Combination: Building Your Deployment Toolkit
Getting your machine learning model deployed effectively usually needs a mix of tools. There’s no one-size-fits-all; the best approach depends on your situation. You might use TensorFlow Serving to serve your model, Docker and Kubernetes for containerization, and a CI/CD pipeline for automated deployment. The key is choosing tools that work well together and fit your team’s skills and resources.
To help you navigate the options, let’s take a closer look at some popular tools:
Top Machine Learning Model Deployment Tools
An overview of the most widely used tools for machine learning model deployment across different categories, including their key features and best applications
Tool
Category
Key Features
Ideal Use Cases
Learning Curve
TensorFlow Serving
Model Serving
Optimized for TensorFlow models, efficient inference
This table summarizes some of the key players in the model deployment space. As you can see, there’s a tool for every stage of the process. Choosing the right combination will significantly streamline your workflow and help you get your models out into the world.
Monitoring Models That Stand the Test of Time
So, you’ve deployed your machine learning model. Congrats! But the journey doesn’t end there. Keeping it effective with all the real-world data changes is the real challenge. You need some serious monitoring to catch and fix issues before they bug your users. This section dives into how to build monitoring systems that keep your models in tip-top shape. Want to learn more about the business side of things? Check out this article on How to master the business impact of Machine Learning.
Key Metrics for Model Monitoring
Not all models are created equal, so they need different metrics. For classification models, you’ll want to keep an eye on accuracy, precision, and recall. These tell you how well your model is picking out what it’s supposed to.
On the other hand, regression models use metrics like mean squared error (MSE) or R-squared. These focus on how well the model predicts continuous values.
No matter the model, keeping an eye on data drift is essential. Data drift happens when your live data starts looking different from your training data. This can really mess with performance. Think of a fraud detection model trained on pre-pandemic data. Post-pandemic spending habits would likely throw it off.
Implementing Automated Monitoring and Alerting
Good monitoring means automating things. Set up a system to continuously track those metrics and send alerts when things go sideways. This helps prevent small issues from becoming big headaches.
But, be careful of alarm fatigue. Too many alerts, and you’ll start ignoring them, even the important ones. Keep your alerts targeted and actionable.
Retraining, A/B Testing, and Deprecation
Models need regular tune-ups. Set up retraining schedules based on data drift, performance dips, and your business needs.
A/B testing is a great way to check out new model versions. Run your new model alongside your old one and compare how they do with real data. Then, you can decide when to make the switch.
Eventually, models get old. Have a plan for graceful deprecation. This could mean slowly moving users to the new model or keeping the old one around for a specific group.
Feedback Loops: The Engine of Continuous Improvement
The best monitoring systems use feedback loops. Take what you learn from your live data and use it to improve the model, the training data, or even the whole pipeline. This constant learning is key to keeping your model relevant and valuable.
For example, feedback from a customer churn prediction model can help you fine-tune the features you’re using, or even find new factors that contribute to churn. By connecting production performance and model development, you create a system that’s always learning and getting better.
Conquering Deployment Challenges Before They Conquer You
Deploying a machine learning model can feel like the final boss battle in a video game. You’ve trained your champion model, leveled up its skills, and now it’s time to release it into the real world. This is where many promising models face challenges that can derail even the most meticulously crafted projects.
Technical Hurdles: Scaling and Performance
One major challenge is scaling infrastructure. Predicting user load can be tricky. Think of a sudden surge of users on a shopping app during a flash sale. Your model needs to handle these peaks without slowing down or crashing. This requires careful resource management and choosing the right deployment strategy, whether it’s cloud VMs, Kubernetes, or serverless functions.
Another technical hurdle is ensuring consistent performance. Your model might perform flawlessly in testing but struggle in production due to differences in hardware, software, or data.
Organizational Challenges: Bridging the Gap
Beyond technical issues, organizational challenges can also cause deployment headaches. A common issue is the disconnect between data science and engineering teams. Data scientists focus on building models, while engineers handle deployment.
This separation can lead to miscommunication, integration problems, and delays. For example, a model might require specific libraries or dependencies that aren’t available in the production environment.
Strategies For Success: Proactive and Collaborative
So, how do you conquer these challenges? One key is proactive planning. This means thinking about deployment early in the development process, not just as an afterthought. Consider factors like scalability, performance requirements, and potential integration issues.
Collaborating closely between data science and engineering teams is also essential. This ensures everyone is on the same page and that the model is designed with deployment in mind. This might involve establishing clear communication channels, shared tools, and joint responsibility for the deployment process.
Another important strategy is incremental deployment. Instead of launching a full-fledged model all at once, start with a smaller pilot deployment. This allows you to test the model in a real-world setting, identify potential issues, and gather feedback before scaling up. This iterative approach minimizes risk.
Troubleshooting and Prevention: Addressing Common Issues
Even with the best planning, problems can arise during deployment. Common issues include dependency conflicts, performance bottlenecks, and data inconsistencies. Having a clear troubleshooting process is crucial.
This might involve logging errors, monitoring performance metrics, and having a rollback plan in case things go wrong. However, the best approach is to prevent problems. This means implementing robust testing procedures, validating data quality, and using version control.
Real-World Success Stories: Turning Disasters into Triumphs
Many organizations have turned potential deployment disasters into success stories through cross-functional collaboration and smart planning. For instance, a retail company successfully deployed a personalized recommendation model by creating a dedicated deployment team.
This team, with representatives from data science, engineering, and product, worked together to address technical and organizational challenges. Another example is a financial institution that avoided a major outage by implementing incremental deployment and rigorous testing. This allowed them to catch and fix performance bottlenecks. These examples demonstrate the power of proactive planning and collaboration.
Ready to transform your AI aspirations into tangible business outcomes? Explore how NILG.AI can empower your organization. Visit us at https://www.nilg.ai to learn more.
Special offers, latest news and quality content in your inbox.
Signup single post
Recommended Articles
Article
Transform Your Growth with custom ai software development in 2026
Apr 1, 2026 in
Guide: Explainer
Explore how custom ai software development can boost efficiency, cut costs, and deliver measurable value - find trusted partners and practical steps for 2026.
Discover how AI for customer service can transform your support operations. Learn practical strategies to reduce costs, improve satisfaction, and drive growth.
How Might We Statements: Turn Challenges into Opportunities
Mar 15, 2026 in
Guide: Explainer
Discover how might we statements transform complex challenges into real opportunities. Learn practical crafting tips, workshops, and real-world examples.
We use cookies on our website to give you the most relevant experience by remembering your preferences and repeat visits. By clicking “Accept All”, you consent to the use of ALL the cookies. However, you may visit "Cookie Settings" to provide a controlled consent.
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. These cookies ensure basic functionalities and security features of the website, anonymously.
Cookie
Duration
Description
cookielawinfo-checkbox-analytics
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics".
cookielawinfo-checkbox-functional
11 months
The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional".
cookielawinfo-checkbox-necessary
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookies is used to store the user consent for the cookies in the category "Necessary".
cookielawinfo-checkbox-others
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Other.
cookielawinfo-checkbox-performance
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Performance".
viewed_cookie_policy
11 months
The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data.
Functional cookies help to perform certain functionalities like sharing the content of the website on social media platforms, collect feedbacks, and other third-party features.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors.
Analytical cookies are used to understand how visitors interact with the website. These cookies help provide information on metrics the number of visitors, bounce rate, traffic source, etc.
Advertisement cookies are used to provide visitors with relevant ads and marketing campaigns. These cookies track visitors across websites and collect information to provide customized ads.